
We have already entered a new phase in the Artificial Intelligence revolution; the industry is now focused on Agentic AI: autonomous agents capable of reasoning, planning, and executing complex tasks on behalf of a user.
But here is the brutal truth: Agents are fragile. If you ask an agent to “analyze the risk of our supply chain,” and it relies solely on a loose collection of PDFs or a messy data lake, It will probably drift and hallucinate because it lacks boundaries.
To work effectively Agentic AI doesn’t just need better prompts; it needs a “Data Constitution”. It needs a set of immutable laws, a structural framework that defines what is true, what is allowed, and how concepts relate to each other.
For some projects, that Constitution has to be implemented with a Data Catalog and additional architecture tools. For a vast majority of projects, we have a secret weapon. We already have that Constitution. It’s called the Oracle Database, and its “articles” are the Relational Model.
Context: the Myth of the “Vector Silo”
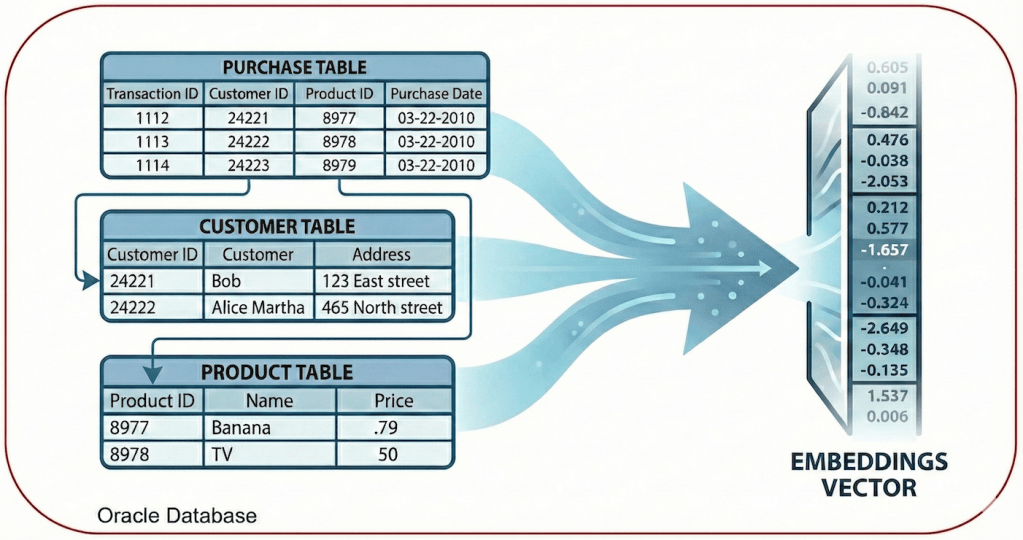
In the early rush to adopt GenAI, many organizations built “Vector Silos.” They took their enterprise data, extracted it into flat files, chopped it into chunks, vectorized it, and dumped it into a specialized vector database.
This approach is dangerous for Agentic AI. Why? Because you strip the data of its integrity.
When you move data out of the relational engine, you lose the constraints that guarantee its quality. You end up with a “soup” of vectors that might represent outdated information, duplicate records, or data that violates business rules. If your AI agent acts on this data, it’s acting on a hallucination.
Quality Embeddings Start with Relational Integrity
This is where a converged database like Oracle changes the game, handling relational, JSON, Graph, Spatial, and Vectors in a single engine. Why does this matter for your AI? Because garbage in, garbage out (if you feed your model poor quality data, you will inevitably get poor quality results) applies to vectors too.
Let’s imagine you want to create a vector embedding to search for “product sales”. You want to combine the description of the product with its category and region to give the AI full context.
In a flat file approach, you might unknowingly vectorize a record where the “Category” is missing (no value) or the “Region ID” has a wrong value. So you create the vector “polluted,” leading the AI to make very wrong connections.
In Oracle, we enforce the “Data Constitution” before the vector is born. Look at this table structure:
CREATE TABLE product_sales ( id NUMBER PRIMARY KEY, product_name VARCHAR2(100) NOT NULL, category VARCHAR2(50) NOT NULL, region_id NUMBER, sale_date DATE CHECK (sale_date > TO_DATE('2000-01-01', 'YYYY-MM-DD')), vector_desc VECTOR, CONSTRAINT fk_region FOREIGN KEY (region_id) REFERENCES regions(id));
When we generate an embedding from this data, we have guarantees:
- NOT NULL Constraints: We guarantee that the vector represents a complete thought. The product name and category must exist.
- Foreign Keys: The region_id ensures that the sale is linked to a real region that exists in our master data.
- Data Types: We know the date is a valid date, not a random string.
When you generate the embedding inside the database using SQL, you are encoding verified truth:
UPDATE product_salesSET vector_desc = VECTOR_EMBEDDING( minilm_l12_v2 USING (product_name || ' in category ' || category) AS input);
So this vector is a mathematical representation of a validated, consistent business fact. And all vectors can be compared with each other sematically, in an effective way, because their encoding (the calculation of embedding generation) is extremely precise.
Generating Embeddings Where the Data Lives
Another critical aspect of this “Constitution” is governance. If you have to export data to an external Python process to generate embeddings, you break the chain of custody. Oracle Database 26ai allows us to import ONNX models (like all_MiniLM_L12_v2) directly into the database kernel.
EXEC DBMS_VECTOR.LOAD_ONNX_MODEL( 'DM_DUMP', 'all_MiniLM_L12_v2.onnx', 'minilm_l12_v2', JSON('{"function" : "embedding", ...}'));
By bringing the model to the data (instead of moving data to the model), we ensure that:
- Security is maintained: The data never leaves the encrypted, governed database layer.
- Consistency: As soon as a transaction inserts a new row, a trigger or a later batch job can generate the vector. The “AI memory” can be kept in sync with the “Operational memory.”
Hybrid Search: The Checks and Balances
Finally, a good Constitution needs a “judicial system” to interpret the laws. In the world of AI, this is Hybrid Search. Semantic search (vector search) is amazing at finding meaning and intent. If I search for wireless headphones, it finds bluetooth earbuds. That’s great. But Agentic AI often needs to be constrained by hard facts. You might want to ask: “Find me wireless headphones sales, BUT only in the last month, AND only in region 1.”
If you rely purely on a vector database, filtering by exact dates or specific IDs is often slow or inaccurate (post-filtering). In Oracle 26ai you can combine the magic of AI with the deterministic power of SQL:
SELECT product_name, category, sale_date, VECTOR_DISTANCE(vector_desc, VECTOR_EMBEDDING(minilm_l12_v2 USING 'wireless headphones' AS input), COSINE) AS similarity_scoreFROM product_salesWHERE region_id = 1 AND sale_date > SYSDATE - 30 AND VECTOR_DISTANCE(vector_desc, VECTOR_EMBEDDING(minilm_l12_v2 USING 'wireless headphones' AS input), COSINE) < 0.3ORDER BY similarity_scoreFETCH FIRST 10 ROWS ONLY;
This is: of the sales in region 1 that occurred in the last 30 days, filter those that are semantically close to “wireless headphones” . Return the product_name, sales date, category and similarity score of the 10 closest matches.
So here, the WHERE clause acts as the guardrail. It physically prevents the AI from seeing data it shouldn’t, or from considering irrelevant timeframes. It restricts the search space to our “constitutional reality”.
Wrapping up
The future of AI isn’t just about having the smartest model; it’s about having the most reliable data.
By leveraging the converged database, we can ensure that every vector we generate is backed by the full power of the relational model; integrity constraints, data types, and security. We turn our database from a simple storage container into the intelligent, governed brain of our AI Agents.
Eventually AI agents don’t fail because models are weak, but because data has no constitution.
